
مروری بر کتابخانههای محبوب علم داده در پایتون:
وقتی که صحبت از یادگیری ماشین، هوش مصنوعی، یادگیری عمیق و علوم داده به میان میاید، زبان برنامه نویسی پایتون همچنان پیشرو است.براساس سایت Buildwith.com چهلوپنج درصد از شرکتهای فناوری استفاده از Python برای پیاده سازی هوش مصنوعی و یادگیری ماشین ترجیح می دهند. پیتر نورویگ، مدیر کیفیت جستجو در Google بیان میکند که پایتون از ابتدا بخش مهمی از گوگل بوده و با رشد و تکامل سیستم همچنان پابرجاست. امروز مهندسهای Google از پایتون استفاده میکنند و ما به دنبال افراد بیشتری هستیم که مهارت این زبان را داشته باشند.
به همین دلیل، ما تصمیم گرفتهایم مجموعه ای را برای بررسی کتابخانههای برتر پایتون در چندین دسته شروع کنیم که در بخشهای بعدی به کتابخانههای یادگیری ماشین، یادگیری عمیق و یادگیری تقویتی خواهیم پرداخت (به زودی)
البته، این لیستها کاملاً ذهنی هستند زیرا بسیاری از کتابخانهها میتوانند به راحتی در چندین دسته قرار گیرند.
10 کتابخانه برتر علم داده Python به زبان پایتون براساس استفاده مشارکت کنندگان، کامیت ها و اندازه در GitHub
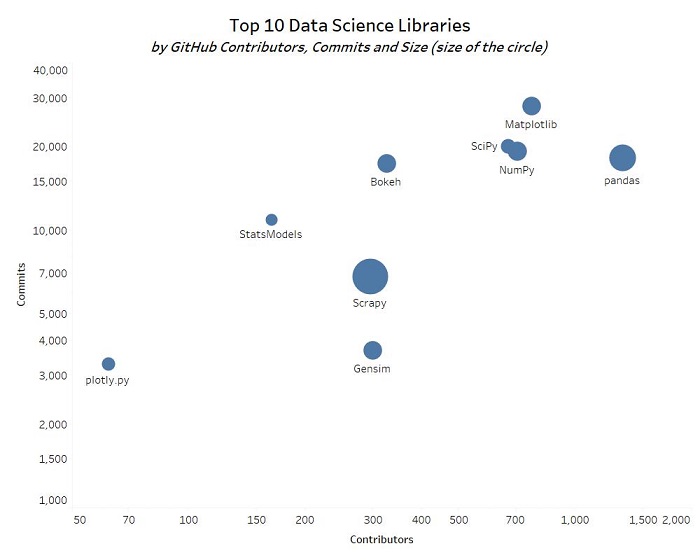
پایتون به طور دقیق پکیجهای زیادی در خود دارد، بیش از 255 هزار پکیج که در دامنه وسیعی از حوزهها منتشر شده است. همانطور که به موضوع Data Science میپردازیم، میخواهیم توجه شما را به برخی از برترین کتابخانههای پایتون جلب کنیم که مورد استفاده گسترده مخاطبان زیادی از جمله دانشمندان داده، محققان، تحلیلگران و بسیاری دیگر قرار میگیرند.
۱- Pandas در گیت هاب Contributors–1328,Commits–18162,Stars–16890:
وظیفه اصلی: دستکاری (پیش پردازش) و تجزیه و تحلیل دادهها

این نام از اصطلاح “PanelData” مشتق شدهاست، دادههای پانلی اصطلاحی در اقتصادسنجی است که برای مجموعه دادهها که شامل مشاهدات در چندین بازه زمانی برای افراد استفاده میگردد. Pandas یک کتابخانه منبع باز با قابلیتهای عالی دستکاری و تجزیه و تحلیل داده است، که استفاده از آن را آسان، انعطاف پذیر و سریع میکند. با استفاده از این کتابخانه، میتوانید وظایفی مانند پیش پردازش، دستکاری و کارهای نمایش را روی دادههای عددی و همچنین سریهای زمانی انجامدهید.
Pandas دارای چندین ویژگی است، مانند:
- فراهمکننده یک شی DataFrame برای دستکاری و نمایهسازی دادهها
- ارائه مجموعهای از ابزارها برای خواندن و نوشتن دادهها در ساختار دادههای حافظه و در قالبهای مختلف فایل
- ادغام و پیوستن کارآمد مجموعه دادهها
- بازسازی انعطاف پذیر مجموعه دادهها
- هم ترازی هوشمند دادهها و مدیریت مقادیر از دسترفته برای سازماندهی بهتر دادهها
آخرین ورژن ارائه شده : 4-1-1
۲- Numpy:
وظیفه اصلی: پاکسازی و دستکاری دادهها

NumPy یک کتابخانه قدرتمند منبع باز پایتون برای محاسبات علمی با آرایه های n بعدی است و مجموعه گستردهای از ابزارها را برای عملیات عددی و دستیابی به عملکرد بهتر و زمان اجرای سریعتر را ارائه میکند.NumPy در دامنه وسیعی از حوزهها مانند رایانش علمی ، علم داده ، یادگیری ماشین، تجسم دادهها، تجزیه و تحلیل دادهها و موارد دیگر مورد استفاده قرار میگیرد.
مهمترین ویژگی های اصلی NumPy عبارتند از:
- مجموعهای از عملکردهای استاندارد و پیشرفته را برای آرایهها فراهم میکند.
- از طیف گستردهای از سیستم عاملها، محیطها و سخت افزارها پشتیبانی میکند.
- syntax قابل فهم
- community بسیار قوی از صدها کاربر فعال که در این پروژه مشارکت دارند.
آخرین ورژن: 1.19.4
۳- Contributors–771, Commits–27937, Stars–8224) Matplotlib):

Matplotlib یک کتابخانه معروف نمودار منبع باز در ابزارهای پایتون است. Matplotlib هنگام انجام وظایف ریاضی به خوبی با NumPy همگام میشود. یکپارچه سازی را از طریق API قدرتمند خود برای ادغام نمودارهای تولید شده در برنامههای دیگر را ارائه میدهد.
برخی از ویژگیهای برجسته matplotlib عبارتند از:
- طیف گسترده ای از نمودارهای ایستا ، متحرک و تعاملی برای انتخاب ارائه میدهد.
- پشتیبانی از سفارشی سازی و خروجی گرفتن از visualizations
- به ابزارهای اضافی از جمله ابزارهایthird-party اجازه میدهد تا عملکرد اصلی ارائه شده توسط matplotlib را گسترش دهند
- community قوی از توسعه دهندگان فعال که به طور منظم در پروژه مشارکت دارند.

۴- Seaborn – تجسم داده های آماری:

Seaborn یک کتابخانه منبع باز برای تجسم در پایتون است که مبتنی بر matplotlib است و لایه سفارشیسازی دیگری را روی نمودارهای تولید شده توسط matplotlib ارائه میدهد. این کتابخانه تلاش میکند با بهرهگیری از فریم دادهها و آرایهها و انجام طراحیهای مربوطه ، تجسمهای آماری بسیار آموزندهای را برای نمایش متمایز دادهها ارائه دهد.
برخی از ویژگیهای ارائه شده توسط Seaborn عبارتند از:
- ارائه یک مجموعه گسترده از تجسم(visualizations)
- کنترل دقیق نمودارها با ارائه ابزارها و built-in ها
- قابلیت ایجاد انتزاعی سطح بالا برای ایجاد تجسمهای پیچیده
- API برای تجزیه و تحلیل روابط بین متغیرها
آخرین ورژن: 0.11.0
۵- Plotly:

یکی دیگر از کتابخانههای رسم نمودار گرافیکی منبع باز و مفید plotly است. بیش از 30 نوع بصری سازی را شامل می شود که شامل موارد علمی ، سهبعدی،آماری،مالی و … است. این کتابخانه به راحتی مشاهده نمودارهای چشمگیر در Jupyter Notebooks ، فایل های HTML را آسان می کند و حتی میتواند از طریق Chart Studio Cloud بصورت آنلاین میزبان شود.
برخی از مزایای اصلی ارائه شده توسط Plotly عبارتند از
- قابلیتهای همکاری گسترده را فراهم میکند
- گزینههای مختلفی را برای به اشتراکگذاری و export گرافها ارائه میدهد
- ادغام با IPython برای تعامل
- یک کامیونیتی فعال از توسعهدهندگان و مشارکتکنندگان
۶- SciPy در گیت هاب(Contributors–670, Commits–20080, Stars–5096):

یک کتابخانه پایتون چند دامنهای و منبع باز برای Data Science است که علوم، ریاضیات و مهندسی را پوشش میدهد. اجزای اصلی سازنده اکوسیستم SciPy NumPy ، SciPy Library ،Matplotlib ،IPython SymPy و Pandas هستند که به شما امکان میدهد در دامنههای ذکر شده به طور کارآمد مورد استفاده قرارگیرد.
توسعهدهندگان به عنوان یک کتابخانه کاربرپسند، میتوانند به راحتی از مزایای مختلف ارائه شده توسط SciPy بهرهمند شوند، از جمله:
- پشتیبانی عالی از طیف گستردهای از بلاکهای ساختاری و عملیات شامل محاسبات با عملکرد بالا و تضمین کیفیت
- شروع کار با انبوهی از توابع و زیر برنامههای اماده
- پشتیبانی از جبر،حساب، معادلات دیفرانسیل
- پشتیبانی از بهینهسازی دادهها، یکپارچهسازی، درونیابی و اصلاحاتگ
اگر میخواهید اعداد را در کامپیوتر دستکاری کنید و نتایج را نمایش یا منتشر کنید، سعی کنید SciPy را امتحان کنید!
آخرین ورژن: 1.5.4
۷- Contributors–295, Commits–6802, Stars–30014) Scrapy ):

اسکرپی یک چارچوب سریع سطح بالای خزنده وب و کرولینگ وب است که برای وب سایتها و استخراج دادههای ساختار یافته از صفحات آنها استفاده میشود و می تواند برای اهداف گستردهای از داده کاوی گرفته تا مانیتورینگ و آزمایش خودکار مورد استفاده قرارگیرد.

۸- Statsmodels:
Statsmodels یک ماژول منبع باز مبتنی بر آمار است که کلاسها و توابع مختلفی برای تجزیه و تحلیل آماری و اکتشاف دادهها ارائه میدهد. این ماژول مدلهایی چون رگرسیون خطی، مدلهای گسسته، تجزیه و تحلیل سری زمانی، تجزیه و تحلیل Survival و بسیاری از مدلهای دیگر را شامل میشود.
برخی از ویژگیهای اصلی statsmodels عبارتند از:
- ارائه تجزیه و تحلیل آماری قوی، آزمون ها و قابلیتهای تخمین مدل
- انواع آزمونها برای مدل، مانند goodness-of-fit، نرمال بودن و …
- پشتیبانی از مدلهای بیشتر چون مدلهای خطی مقاوم، مدلهای خطی مخلوط .
- آمار غیرپارامتری
۹- Scikit-learn:

این یک کتابخانه پایتون است که با NumPy و SciPy مرتبط است.این کتابخانه به عنوان یکی از بهترین کتابخانهها برای کار با دادههای پیچیده در نظر گرفته شده است.از ابزارهای ساده و کارآمد برای تجزیه و تحلیل دادههای پیشبینی شده استفاده مینماید.بسیاری از روشهای آموزشی مانند رگرسیون لجستیک و نزدیکترین همسایگان پیشرفتهای کمی داشتهاند.
ویژگی های Scikit-Learn:
- اعتبار سنجی متقابل cross validation: روش های مختلفی برای بررسی صحت مدلهای تحت نظارت بر دادههای دیده نشده وجود دارد.
- الگوریتمهای یادگیری بدون نظارت Unsupervised learning algorithms: از خوشهبندی ، تحلیل عاملی (factor analysis ،PCA) گرفته تا شبکه های عصبی بدون نظارت.
- استخراج ویژگی Feature extraction: برای استخراج ویژگیها از تصاویر و متن مفید است (به عنوان مثال bag of words)
۱۰- TensorFlow:
وظیفه اصلی: ساخت مدل های یادگیری عمیق
TensorFlow توسط Google ارائه شده است ، ابزاری عالی برای توسعه و آموزش مدلهای یادگیری ماشین است و برای بسیاری از سیستم عاملها مانند تلفن همراه، اینترنت اشیا و سایر برنامهها در دسترس است. این برنامه میتواند از عهده کارهایی از قبیل تشخیص شی، تشخیص گفتار و موارد دیگر برآید.
با استفاده از معماری انعطافپذیر TensorFlow، توسعهدهندگان میتوانند به راحتی و براساس نیاز، سخت افزار را مقیاس بندی کنند.
مزایای اصلی ارائه شده توسط TensorFlow عبارتند از:
- ساختمان مدل را تسهیل میکند
- شامل ابزارهایی از ایده تا استقرار نهایی است
- منابع قدرتمندی برای تحقیق ارائه میدهد
- با پشتیبانی عالی ارائه میشود
- از چندین محصول معروف Google مانند Google Photos و جستجوی صوتی پشتیبانی میکند.


عالی بود